- 수강한 강의
: Ch 02. 분류 분석 - 03. 분류 분석과 로지스틱 회귀 모델 - 2 / Ch 02. 분류 분석 - 04. Logistic Regression을 이용한 전설의 포켓몬 분류 실습 / Ch 02. 분류 분석 - 05.비지도 학습과 K-means 군집 분석
오늘은 분류 분석에 분류 분석과 로지스틱 회귀 모델, Logistic Regression을 이용한 전설의 포켓몬 분류 실습, 비지도 학습과 K-means 군집 분석에 관한 내용을 작성해보겠습니다. 내용에 많은 오류가 있을 수 있습니다.
Ch 02. 분류 분석 - 03. 분류 분석과 로지스틱 회귀 모델 - 2
회귀 분석 기반 모델의 전처리 방법
원-핫 인코딩
다음의 사진으로 나와 있는 데이터로 회귀 분석에 이용한다면, 이름 데이터는 사용하기 어려우므로 지우는 것이 좋다.아래의 사진이 데이터 셋에서 이름의 컬럼을 제거한 데이터 셋이다.
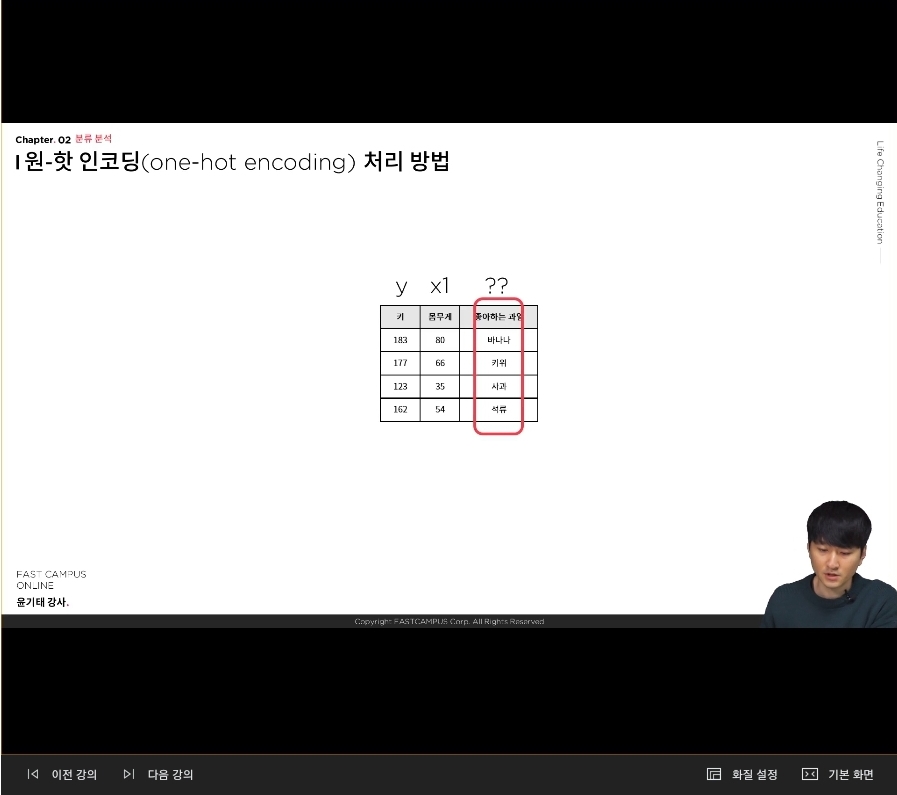
키를 y 값으로 둔다거나 몸무게를 y 값으로 둘 수 있다. '좋아하는 과일'을 x2로 두고 싶은데 컴퓨터는 '바나나, 키위, 사과, 석류'를 인식할 수 없다. 왜냐면 컴퓨터는 0과 1로 이루어진 세상이기 때문에 '바나나, 키위, 사과, 석류'라는 카테고리 컬한 범주 형인 데이터를 변환해주어야 한다. 그래서 이것을 변환해주는 방법의 하나가 원-핫 인코딩이다.
다음 사진이 '좋아하는 과일' 컬럼을 활용한 원-핫 인코딩한 결과값이다.
원-핫 인코딩은 좋아하는 과일의 컬럼을 다음과 같이 변환하여 0과1 이라는 수치로 변환해서 보여주게 된다. 이렇게 되면 x의 사이즈는 4개가 된다.
다음과 같은 데이터를 만들어 낼 수 있다.
원-핫 인코딩 : 이 벡터 중에 하나만 켜져 있다라는 의미이기 때문에 원-핫 인코딩이라고 한다.좋아하는 과일이 하나가 아닌 다수일 경우에는 멀티 레이블 인코딩 (Multi-label Encoding) 처리 방법을 사용한다.
다음의 사진이 멀티 레이블 인코딩 처리 방법이다.
분류 모델의 평가 방법
다음은 일반적인 분류 모델의 평가 방법을 알아보기 전에 로지스틱 회귀 모델이라는 것은 회귀 모델이기도 하고, 분류 모델이기도 한 특성을 가지고 있으므로 모든 일반화 될 수 있는 분류 모델과는 조금 다른 모델 자체만의 고유한 평가들이 존재한다.일반적인 회귀 분석에서는 결정계수 혹은 Rnaci를 이용해서 평가한다. 이것과 유사한 방법으로 학습 결과의 유의성을 검정할 수 있거나 각 피처들에 대해서 T-test를 해볼 수 있고, 결정계수와 굉장히 비슷한 역할을 하는 맥하든 계수가 있는데 그런것들로 마치 회귀분석처럼 평가를 한다.


여러 가지 분류 모델을 동일한 기준으로 평가하는 것은 confusion matrix를 활용하는 것. 0과 1 분류하는 이진 분류에서 1이라는 것을 예측하는 상황에 대해서 나타낸 것.행 데이터는 실제 분류 값이 1이라는 것에 대한 Postitive, Negative를 나타낸 것이고, 열 데이터는 분류 모델의 예측값이 실제로 positive인지 Negative인지를 나타낸 것
이러한 4가지 성질을 이용한 지표를 만들어 낼 수 있다.

다음은 예제이다.
어떤 병원에서 어떤 분류 모델을 개발해서 '당신은 암에 걸렸습니다'라는 명제를 판단해 주는 모델이다.
그리고 만들 모델을 가지고 200명을 대상으로 분류를 했다. 진단에 적용한 결과가 다음과 같이 나온 것이다.
정확도를 계산을 해보면 98~99 정도가 나올 것이고, 그렇다면 정확도가 무려 99%라는 모델이다. 그런데 수치적으로는 굉장히 잘 된 모델이지만 여기에는 함정이 있다. 바로 False Positive에 속하는 사람들 때문이다. 실제로는 암에 걸렸는데 병원에서는 암이 아니라고 진단을 받은 사람이기 때문에 이 판단은 굉장히 치명적인 판단이 된다. 이러한 상황에서 필요한 것이 정밀도가 된다.
정밀도는 0.8 정도가 나온다. 재현도와 특이도도 마찬가지로 분류의 상황마다 다른 판단 기준들이 있는데 이런 것들을 고려하기 위해 존재하는 수치들. 그리고 이것들을 어떻게 분리하느냐에 따라서 어떻게 적용하느냐에 따라서 잘 관찰하는 것이 데이터 분석가의 몫이 된다.
F1 스코어 혹은 AUC라는 조금 더 발전된 분류에 객관적인 수치 판단을 위해서 고안된 지표들이 있다. 그리고 F1 Score는 단순히 precision과 recall의 조합 평균을 나타낸 것이라고 봐도 된다. 따라서 정밀도와 재현도라는 수치는 적절하게 균형을 맞춰서 보고 싶은 분류 문제가 있는 경우에 적용하면 되고, 문제는 AUC라는 것이다.
빗금친 영역의 넓이가 된다. Threshold의 값에 따라 달라진다. decision boundary는 일반적으로 0.5로 한다. 이것을 분류하는 기준을 0.6으로 했을 경우, 0.7로 했을 경우의 값을 비교해본다. 다음의 설명을 그래프로 나타내보자면 다음과 같다.
decision boundary를 무엇으로 두느냐에 따라서 요런 식으로 꺾여지는 그래프가 나오게 된다. 데이터가 많으면 많아질수록 곡선의 형태가 나오게 된다. 곡선을 확대하게 되면 다음과 같이 나오게 된다.
가운데 있는 선이 decision boundary가 된다. 왼쪽의 곡선이 정답에 대한 확률 곡선이 되는 것이고, 오른쪽 곡선이 오답에 대한 확률 곡선이 된다. decision boundary가 0.5로 되면 정확히 쌍곡선의 가운데 위치한다.
Ch 02. 분류 분석 - 04. Logistic Regression을 이용한 전설의 포켓몬 분류 실습
다음에는 전설의 포켓몬 분류 실습을 실행한다.
우선 포켓몬 데이터 셋을 먼저 로드 시켜준다.%matplotlib inline import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import warnings warnings.filterwarnings("ignore") df = pd.read_csv("https://raw.githubusercontent.com/yoonkt200/FastCampusDataset/master/Pokemon.csv") df.head()# Name Type 1 Type 2 Total HP Attack Defense Sp. Atk Sp. Def Speed Generation Legendary 0 1 Bulbasaur Grass Poison 318 45 49 49 65 65 45 1 False 1 2 Ivysaur Grass Poison 405 60 62 63 80 80 60 1 False 2 3 Venusaur Grass Poison 525 80 82 83 100 100 80 1 False 3 3 VenusaurMega Venusaur Grass Poison 625 80 100 123 122 120 80 1 False 4 4 Charmander Fire NaN 309 39 52 43 60 50 65 1 False
Feature Description
Name : 포켓몬 이름
Type 1 : 포켓몬 타입 1
Type 2 : 포켓몬 타입 2
Total : 포켓몬 총 능력치 (Sum of Attack, Sp. Atk, Defense, Sp. Def, Speed and HP)
HP : 포켓몬 HP 능력치
Attack : 포켓몬 Attack 능력치
Defense : 포켓몬 Defense 능력치
Sp. Atk : 포켓몬 Sp. Atk 능력치
Sp. Def : 포켓몬 Sp. Def 능력치
Speed : 포켓몬 Speed 능력치
eneration : 포켓몬 세대
Legendary : 전설의 포켓몬 여부
Feature Description다음은 포켓몬 데이터 셋에 존재하는 Feature를 설명한 내용이다.로드한 데이터 셋을 가지고 데이터 전처리를 실행시켜준다. 우선 일부 데이터의 타입을 변경시켜준다.
df['Legendary'] = df['Legendary'].astype(int) df['Generation'] = df['Generation'].astype(str) preprocessed_df = df[['Type 1', 'Type 2', 'Total', 'HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed', 'Generation', 'Legendary']] preprocessed_df.head()Type 1 Type 2 Total HP Attack Defense Sp. Atk Sp. Def Speed Generation Legendary 0 Grass Poison 318 45 49 49 65 65 45 1 0 1 Grass Poison 405 60 62 63 80 80 60 1 0 2 Grass Poison 525 80 82 83 100 100 80 1 0 3 Grass Poison 625 80 100 123 122 120 80 1 0 4 Fire NaN 309 39 52 43 60 50 65 1 0데이터 타입을 바꾼 데이터 셋에서 Type 1의 값들을 원-핫인코딩 시켜준다.
# one-hot encoding example encoded_df = pd.get_dummies(preprocessed_df['Type 1']) encoded_df.head()Bug Dark Dragon Electric Fairy Fighting Fire Flying Ghost Grass Ground Ice Normal Poison Psychic Rock Steel Water 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0그런데 포켓몬 데이터 셋에는 포켓몬 타입이 2개가 존재한다. 이러한 타입은 Type1, Type2로 나눠어서 표시가 되어있다. 이렇게 나눠진 데이터를 리스트 형식으로 묶어서 표현해본다.
# pokemon type list 생성 def make_list(x1, x2): type_list = [] type_list.append(x1) if x2 is not np.nan: type_list.append(x2) return type_list preprocessed_df['Type'] = preprocessed_df.apply(lambda x: make_list(x['Type 1'], x['Type 2']), axis=1) preprocessed_df.head()Type 1 Type 2 Total HP Attack Defense Sp. Atk Sp. Def Speed Generation Legendary Type 0 Grass Poison 318 45 49 49 65 65 45 1 0 [Grass, Poison] 1 Grass Poison 405 60 62 63 80 80 60 1 0 [Grass, Poison] 2 Grass Poison 525 80 82 83 100 100 80 1 0 [Grass, Poison] 3 Grass Poison 625 80 100 123 122 120 80 1 0 [Grass, Poison] 4 Fire NaN 309 39 52 43 60 50 65 1 0 [Fire]다음과 같은 결과값이 Type1과 Type2로 나눠진 데이터를 하나로 합쳐서 표현해준 것이다. 이제 이렇게 합쳐진 데이터가 있기 때문에 기존의 Type1, Type2의 컬럼은 제거해준다. 이러한 데이터를 활용하여 멀티 레이블 인코딩을 해준다.
# multi label binarizer 적용 from sklearn.preprocessing import MultiLabelBinarizer mlb = MultiLabelBinarizer() preprocessed_df = preprocessed_df.join(pd.DataFrame(mlb.fit_transform(preprocessed_df.pop('Type')), columns=mlb.classes_)) preprocessed_df.head()Total HP Attack Defense Sp. Atk Sp. Def Speed Generation Legendary Bug Dark Dragon Electric Fairy Fighting Fire Flying Ghost Grass Ground Ice Normal Poison Psychic Rock Steel Water 0 318 45 49 49 65 65 45 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 405 60 62 63 80 80 60 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 2 525 80 82 83 100 100 80 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 3 625 80 100 123 122 120 80 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 4 309 39 52 43 60 50 65 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0다음의 결과값이 멀티 레이블 인코딩을 한 결과값이다.
다음에는 포켓몬 세대별로 원-핫 인코딩을 실행시킨다.
# apply one-hot encoding to 'Generation' preprocessed_df = pd.get_dummies(preprocessed_df) preprocessed_df.head()Total HP Attack Defense Sp. Atk Sp. Def Speed Legendary Bug Dark Dragon Electric Fairy Fighting Fire Flying Ghost Grass Ground Ice Normal Poison Psychic Rock Steel Water Generation_1 Generation_2 Generation_3 Generation_4 Generation_5 Generation_6 0 318 45 49 49 65 65 45 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 1 405 60 62 63 80 80 60 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 2 525 80 82 83 100 100 80 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 3 625 80 100 123 122 120 80 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 4 309 39 52 43 60 50 65 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0다음의 결과가 세대(Generation)으로 원-핫 인코딩한 결과값에 해당하는 것이다.
요번에는 각 피처들을 표준화 시킨다.
from sklearn.preprocessing import StandardScaler # feature standardization scaler = StandardScaler() scale_columns = ['Total', 'HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed'] preprocessed_df[scale_columns] = scaler.fit_transform(preprocessed_df[scale_columns]) preprocessed_df.head()Total HP Attack Defense Sp. Atk Sp. Def Speed Legendary Bug Dark Dragon Electric Fairy Fighting Fire Flying Ghost Grass Ground Ice Normal Poison Psychic Rock Steel Water Generation_1 Generation_2 Generation_3 Generation_4 Generation_5 Generation_6 0 -0.976765 -0.950626 -0.924906 -0.797154 -0.239130 -0.248189 -0.801503 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 1 -0.251088 -0.362822 -0.524130 -0.347917 0.219560 0.291156 -0.285015 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 2 0.749845 0.420917 0.092448 0.293849 0.831146 1.010283 0.403635 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 3 1.583957 0.420917 0.647369 1.577381 1.503891 1.729409 0.403635 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 4 -1.051836 -1.185748 -0.832419 -0.989683 -0.392027 -0.787533 -0.112853 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0
모델 학습을 시키기 위해서 우선 데이터 셋을 분리시켜준다.from sklearn.model_selection import train_test_split # dataset split to train/test X = preprocessed_df.loc[:, preprocessed_df.columns != 'Legendary'] y = preprocessed_df['Legendary'] x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=33) print(x_train.shape) print(x_test.shape)(600, 31) (200, 31)
데이터 셋을 분리시켰다면 Logistic Regression 모델 학습을 시켜준다.그러고 모델 평가를 시켜준다.from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 지표 생성 # Train LR model lr = LogisticRegression(random_state=0) lr.fit(x_train, y_train) # classifiacation predict y_pred = lr.predict(x_test) # classification result for test dataset print("accuracy: %.2f" % accuracy_score(y_test, y_pred)) print("Precision : %.3f" % precision_score(y_test, y_pred)) print("Recall : %.3f" % recall_score(y_test, y_pred)) print("F1 : %.3f" % f1_score(y_test, y_pred))`accuracy: 0.95 Precision : 0.615 Recall : 0.667 F1 : 0.640다음의 값은 모델 평가를 시켜서 나온 정확도, 정밀도, 재현도, F1에 대한 값이 된다.
from sklearn.metrics import confusion_matrix # print confusion matrix confmat = confusion_matrix(y_true=y_test, y_pred=y_pred) print(confmat)[[183 5] [ 4 8]]다음의 결과값은 위에 평가 지표가 어떤 값을 가지고 계산 했는지 알아보기 위해서 confusion_matrix를 활용하여 각 수치에 관한 값을 출력해준것이다.
데이터 셋의 클래스 불균형을 조정해준다.
preprocessed_df['Legendary'].value_counts()0 735 1 65 Name: Legendary, dtype: int64다음의 값을 활용해서 1:1 샘플링을 실행시켜준다.
positive_random_idx = preprocessed_df[preprocessed_df['Legendary']==1].sample(65, random_state=33).index.tolist() negative_random_idx = preprocessed_df[preprocessed_df['Legendary']==0].sample(65, random_state=33).index.tolist() positive_random_idx # 데이터 프레임에서 class가 1인 row의 index값만 가져온 것[796, 537, 704, 164, 262, 429, 542, 707, 705, 264, 551, 430, 418, 163, 424, 706, 157, 545, 431, 710, 708, 702, 156, 699, 428, 703, 538, 420, 795, 540, 793, 270, 798, 544, 794, 426, 711, 797, 799, 552, 712, 709, 419, 425, 414, 415, 550, 700, 539, 416, 541, 543, 701, 553, 417, 422, 549, 162, 792, 269, 421, 158, 427, 263, 423]1:1 샘플링이 끝났으면 다시 데이터 셋을 분리시켜주고 X_train, x_test의 모양을 출력해본다.
# dataset split to train/test random_idx = positive_random_idx + negative_random_idx X = preprocessed_df.loc[random_idx, preprocessed_df.columns != 'Legendary'] y = preprocessed_df['Legendary'][random_idx] x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=33) print(x_train.shape) print(x_test.shape)(97, 31) (33, 31)
데이터 셋을 분리했다면 모델을 재학습시켜준다.# Train LR model lr = LogisticRegression(random_state=0) lr.fit(x_train, y_train) # classifiacation predict y_pred = lr.predict(x_test) # classification result for test dataset print("accuracy: %.2f" % accuracy_score(y_test, y_pred)) print("Precision : %.3f" % precision_score(y_test, y_pred)) print("Recall : %.3f" % recall_score(y_test, y_pred)) print("F1 : %.3f" % f1_score(y_test, y_pred))accuracy: 0.97 Precision : 0.923 Recall : 1.000 F1 : 0.960
다음의 결과값은 불균형 조정을 하고 난 후에 결과값이다. 클래스 불균형 조정과 다른 결과 값이 나오는 것을 확인할 수 있다.# print confusion matrix confmat = confusion_matrix(y_true=y_test, y_pred=y_pred) print(confmat)[[20 1] [ 0 12]]다음은 불균형 조정한 후에 각 위치별 수치를 확인한 결과값이다.
Ch 02. 분류 분석 - 05.비지도 학습과 K-means 군집 분석
군집 분석과 비지도 학습

다음은 군집 분류 분석에 대한 간단한 설명이다.
다음 예시 사진이다. 다음과 같이 데이터가 분류되어 있다.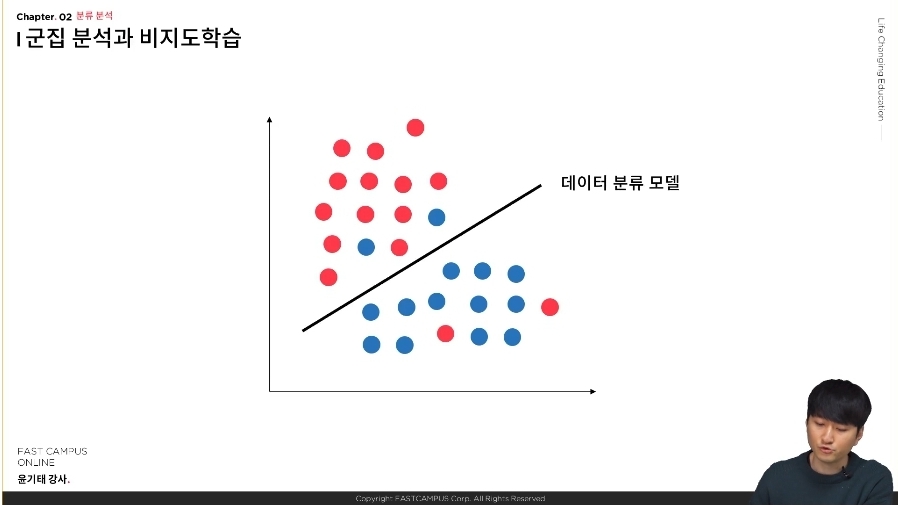
다음과 같이 하나는 분홍색 데이터, 하나는 파란색 데이터를 가지고 있을 때 데이터 분류 모델을 통해서 분류를 할 수 있다. 가장 대표적인 것이 로지스틱 회귀 분류이다. 그리고 만약 클래스가 없는 상황이라면 얼핏 두 개의 그룹이라고 나눌수 있다.
사람이라면 중간에 나눠진 것을 기준으로 두 개로 분류할 수가 있다 하지만 컴퓨터에 경우에는 그것이 불가능하다.Kmeans 군집 분류 분석
주어진 데이터를 k개의 클러스터로 묶는 방식, 거리 차이의 분산을 최소화하는 방식으로 동작, 비슷한 데이터 끼리 묶어주는 군집 분류의 대표적인 예. 정답이 없는 데이터 셋을 대상으로 하기 때문에 비지도 학습의 일부라고 할 수도 있다.kmeans의 학습 방법은 Expectation / Maximization 이 두가지가 있다.

다음과 같은 데이터가 있다고 할 때 Expectation 단계는 사람이 정한 군집의 수대로 군집의 중심을 랜덤하게 배치를 한다.
다음과 같이 임의의 군집 2개를 정한 다음에 나머지 점들을 2개의 군집에 가까운 군집으로 분류를 시킨다.
이렇게 A와 B를 일차적으로 나누것이 Maximization이라고 할 수 있다.
그리고 나머지 군집 마다 평균이 있기 때문에 평균을 정해서 중심점을 다시 정한다. 이러한 과정을 계속 해서 반복하게 되면 다음과 같이 나오게 된다.
이 과정이 kmeans 군집 분류의 학습 과정이다.
Maximization을 한 기준을 보게 되면 kmean 두 데이터 점의 물리적 거리를 구하게 된다. 이것을 바로 유클리드 거리라고 한다.
그림처럼 이차원의 데이터가 아니라 고차원의 피쳐를 가진 데이터에 경우에는 이러한 계산 방식이 별로 효율적이지는 않다. 그래서 점점 비효율적이고 부정확하다는 단점이 있다. 고차원 데이터를 가지고 있을때는 차원 축소를 통해서 kmeans를 적용하거나 조금 더 상위의 분류 모델을 사용하는 것이 일반적이다.
다음 사진 처럼 차원이 너무 많은 상황을 차원의 저주라고 한다.
사람이 상상하게 어려운 차원의 데이터 연산이 이루어지게 되면 모델의 성능이 떨어지거나 과적합이 일어나게 되는 상황이 생기는 데 이러한 상황을 차원의 저주에 걸렸다라고 한다.
차원 축소를 이용한 결과 해석 엘보우 메소드 (elbow method) 실루엣 계수 평가 등...
다음은 elbow method를 설명한 사진이다.
사람이 정하는 k 값을 변경을 한다. k값을 여러개로 바꿔보면서 유클리드한 디스턴스 들의 합을 y축으로 하고 줄어드는 속도가 현저하게 작아지는 경우가 있다. 이 이상의 값을 더 늘려도, 더 많은 군집으로 나눠도 대세에는 크게 영향을 미치지 않는다. 그렇기 떄문에 굽어지는 포인트가 사람을 elbow와 비슷해서 elblow method라는 말이 붙게 된것이다. 다음 포인트가 가장 적당한 군집정도로 나눠졌다는 기준이 되게 된다.
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv("https://raw.githubusercontent.com/yoonkt200/FastCampusDataset/master/Pokemon.csv")
df.head()이렇게 분류 분석에 분류 분석과 로지스틱 회귀 모델, Logistic Regression을 이용한 전설의 포켓몬 분류 실습, 비지도 학습과 K-means 군집 분석에 관한 내용을 작성해보았습니다. 잘못된 부분이 있는 경우 아래 댓글에 알려주시면 수정하도록 하겠습니다.
데이터 분석
홈페이지에서 강의 찾는 방법
패스트 캠퍼스 -> 온라인 -> 올인원 패키지 -> [데이터 분석 강의 보러 가기] -> 직장인을 위한 파이썬 데이터 분석 올인원 패키지 Online.패스트 캠퍼스 - [데이터 사이언스] 직장인을 위한 파이썬 데이터 분석
직장인을 위한 파이썬 데이터 분석 올인원 패키지 Online
'데이터 분석' 카테고리의 다른 글
| 패스트 캠퍼스 직장인을 위한 파이썬 데이터 분석 올인원 패키지 Online 데이터분석 인강 챌린지 참여 후기 (0) | 2021.05.24 |
|---|---|
| [패스트 캠퍼스 수강 후기] 직장인을 위한 파이썬 데이터 분석 올인원 패키지 Online 26일차 (0) | 2021.05.10 |
| [패스트 캠퍼스 수강 후기] 직장인을 위한 파이썬 데이터 분석 올인원 패키지 Online 25일차 (0) | 2021.05.04 |
| [패스트 캠퍼스 수강 후기] 직장인을 위한 파이썬 데이터 분석 올인원 패키지 Online 24일차 (0) | 2021.05.03 |
| [패스트 캠퍼스 수강 후기] 직장인을 위한 파이썬 데이터 분석 올인원 패키지 Online 23일차 (0) | 2021.04.27 |




댓글