- 수강한 강의
: Ch02.Pandas-전처리-10.데이터프레임의 산술연산 / Ch02.Pandas-전처리-11.Select_dtypes / Ch02.Pandas-전처리-12.원핫인코딩의 개념과 get_dummies / Ch02.Pandas-전처리-13.부동산 데이터로 데이터 분석 실습-문제 설명 / Ch02.Pandas-전처리-14.부동산 데이터로터데이터 분석 실습-해설 / Ch03.pandas-시각화-01.데이터 시각화에 대하여 / Ch03.Pandas-시각화-02. colab 한글폰트 깨짐현상 해결 (시각화)
오늘은 Pandas 전처리 방법중에서 데이터프레임의 산술연산, Select_dtype, 원핫인코딩의 개념과 get_dimmies, 실제 부동산 데이터로 데이터 분석을 하는 실습, 데이터 시각화에 대한 설명, colab을 활용하여 시각화를 할때 한글폰트 깨짐현상을 해결하는 방법에 관하여 작성해보겠습니다.
- Ch02.Pandas-전처리-10.데이터프레임의 산술연산
- 데이터프레임의 산술연산은 기본적인 산술연산과 동일하게 적용이 된다.
-
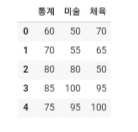
df = pd.DataFrame({'통계': [60, 70, 80, 85, 75], '미술': [50, 55, 80, 100, 95], '체육': [70, 65, 50, 95, 100] }) df- 다음과 같은 데이터 프레임을 작성을 해준다.
type(df['통계'])와 같은 코드를 작성을 하게되면pandas.core.series.Series와 같이 데이터의 컬럼이 Series로 구성되어 있는 것을 확인할 수 있다.-
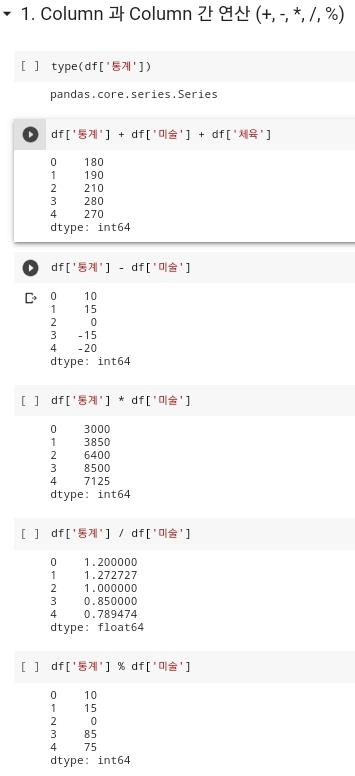
- 위 사진과 같이 데이터내에 있는 컬럼끼리 덧셈, 뺄셈, 곱셈, 나눗셈, 나머지를 구하는 식을 작성을 하게되면 데이터 프레임의 각 컬럼들의 산술연산 값이 제대로 나오는 것을 확인할 수 있다.
-
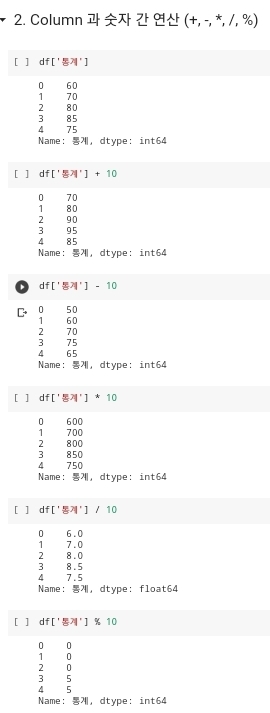
- 데이터 프레임에서 산술연산은 꼭 각 데이터 프레임의 컬럼들끼리만 연산이 되는 것만이 아니다. 특정 컬럼에 특정 정수값을 대입하여 연산을 해도 정확한 결과값이 출력되게 된다. 해당하는 결과에 관한 값은 바로 위 사진을 보게되면 정확한 연산이된 것을 확인할 수 있다.
- 데이터 프레임에 단순 연산만 가능한 것이 아니라 여러 컬럼들을 복합 연산하는 것도 가능하다. 복합 연산을 하고 나온 값을 데이터 프레임에 새로운 컬럼에 대입하여 표현까지 가능하다.
-
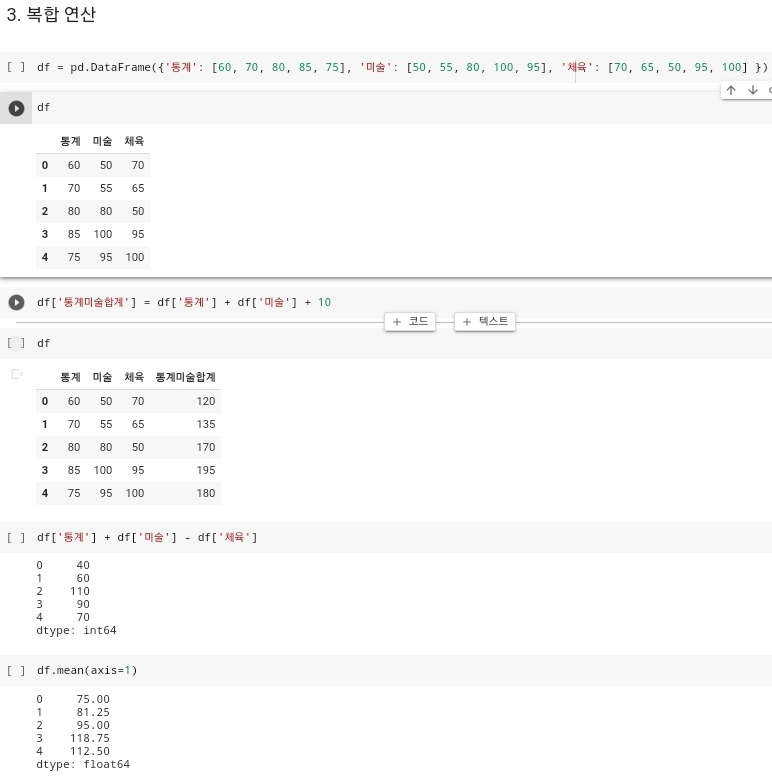
- 해당 사진에 나와있는 것처럼 데이터 프레임 df에서 '통계', '미술' 컬럼과 정수 10을 더한 다음에 '통계미술합계' 라는 새로운 컬럼값에 대입을 한 다음에
df를 작성해서 실행을 하게되면 기존 df 데이터 프레임에 새로운 '통계미술합계' 라는 새로운 컬럼이 생성이 되고, 거기에 해당하는 값들이 채워진 것을 확인할 수 있다. - 그리고 데이터 프레임에서 각 행에 해당하는 값들에 대한 연산이나 각 열에 해당하는 값들에 대한 연산 또한 가능하다. 해당 코드는
df.sum(axis=0) # 각 행의 같은 열 성분에 대한 전체 합df.mean(axis=0) # 각 행의 같은 열 성분에 대한 전체 평균df.sum(axis=1) # 각 열의 같은 행 성분에 대한 전체 합df.mean(axis=1) # 각 열의 같은 행 성분에 대한 전체 평균 -
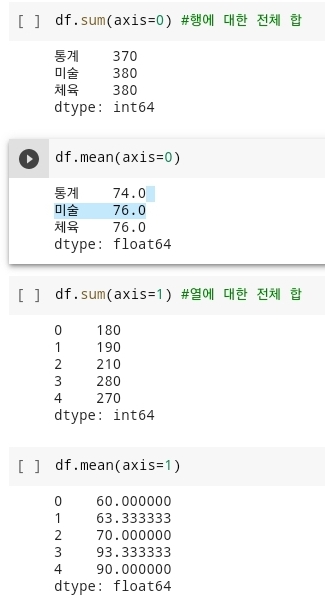
- 다음 사진에 해당 코드의 결과값이다.
- NaN값이 존재할 경우에도 연산이 가능하다.
- 결측값이 존재하는 경우에도 연산은 가능하다. 결측값이 존재하는 데이터 프레임의 연산은 결측값이 존재하는 것에 관한 연산은 결측값이 존재하는 값에 대해서는 최종 결과값도 NaN 값으로 나타나게 된다.
-
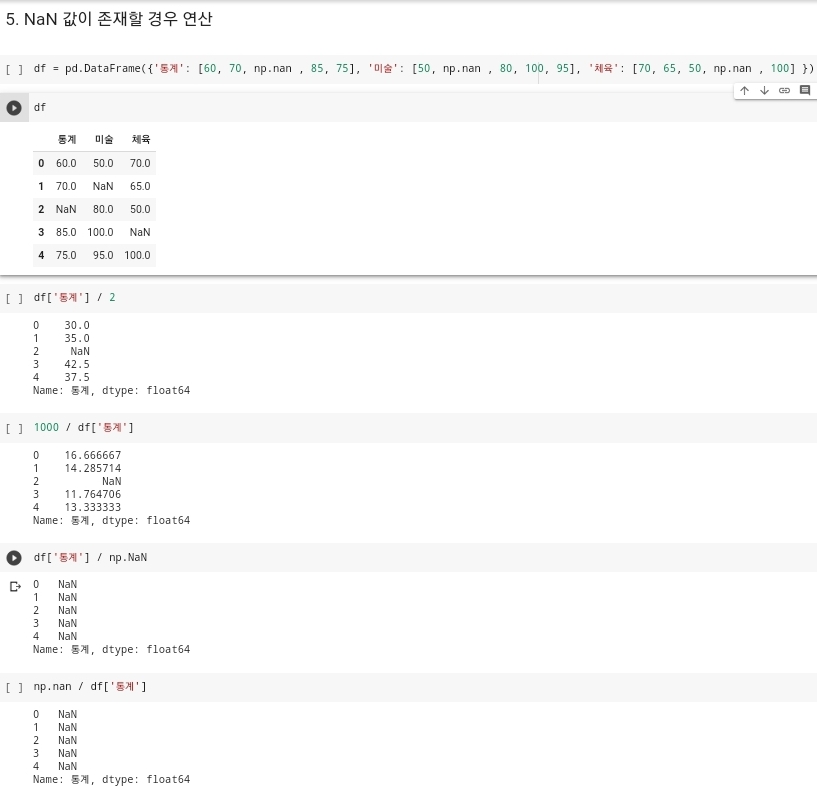
- 다음 사진이 결과에 관한 사진이다. 기존 데이터 프레임에 NaN 값인 결측값니 존재하는 열에 대하여 연산을 진행을 하고 최종값을 보게되면 결측값 없이 실수값이 존재하는 데이터 값들은 정확하게 연산이 되는 것을 확인할 수 있는데, 결측값이 존재하는 값에 관해서는 최종 결과값이 NaN이라는 값으로 나오는 것을 확인할 수 있다.
- 하나의 데이터 프레임만의 연산만 가능한 것이 아니라 여러 데이터 프레임에 관한 연산 또한 가능하다. 하지만 여러 데이터 프레임 연산을 하게 될 경우 주의해야할 것이 있다. 주의해야 할 사항은 각 위치의 데이터 값이 같은 데이터 타입으로 존재해야 연산이 가능하다. 다른 타입으로 존재하게 되면 연산시 오류가 발생하게 된다.
- 해당 상황은 데이터 프레임 연산에서만 발생하는 오류가 아니라, 일반 연산을 실행할 경우에도 발생하는 오류와 동일하게 발생하게 되는 것이다.
- column의 순서가 바꾸어 있는 경우에 관한 연산도 존재가 하게 된다. 이러한 경우에는 각 위치에 성분에 따라서 연산이 진행이 되는 것이 아니라 순서가 다르더라도 컬럼에 존재하는 값에 맞춰서 연산이 진행되게 된다.
-
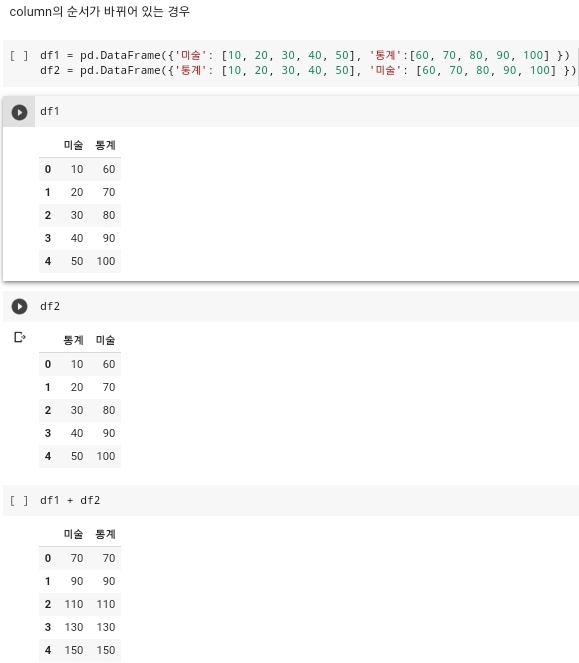
- 사진에서 보이는 것처럼 df1과 df2 라는 column의 순서가 바뀐 두 개의 데이터가 존재한다. 다음의 두 데이터를 더하기 연산을 진행하게 되면 보이는 것처럼 df1의 미술 + df2의 통계 / df1의 통계 + df2의 미술 이렇게 연산이 진행이 되는 것이 아니라, df1의 미술 + df2의 미술 / df1의 통계 + df2의 통계 의 형식으로 진행이 되게 되는 것을 확인할 수 있다. 사진을 보고 알 수있는 상황은 컬럼의 순서가 바꿔서 데이터가 작성이 되었다고 하더라고 연산을 하는 것에 있어서는 컬럼의 순서가 우선순위가 아니라 컬럼명이 같은지가 우선순위로 매겨지다는 것을 확인할 수 있다.
- 데이터 프레임에서 순서가 바뀐 것만 존재하는 것이 아니라, 각 데이터 프레임의 행의 갯수가 다른 경우가 있다. 이러한 경우에는 적은 행의 갯수 데이터 프레임을 기준으로 연산이 진행이 되기 때문에 아무리 행의 갯수가 많다고 하더라도 해당 값들은 모두 NaN, 결측값으로 표현되어 결과값이 나오게 된다.

- Ch02.Pandas-전처리-11.Select_dtypes
- 다음은 Pandas에서 select_dtypes이라는 함수가 존재하게 된다. select_dtypes은 데이터에서 내가 찾고자하는 데이터 타입의 컬럼값들만 찾아서 결과값을 출력하는 함수이다.
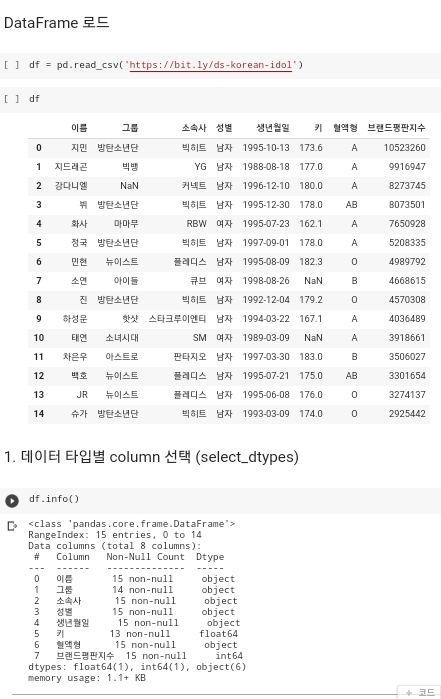
- 다음 사진에 df라는 데이터가 존재하게 되고, 데이터의 정보를 확인을 하게 되면, '이름', '그룹', '소속사', '성별', '생년월일', '혈액형'의 데이터 타입은 'object'이고, '키', '브랜드평판지수'의 데이터 타입은 'float64', 'int64' 이다. 이렇게 데이터 타입을 확인할 수가 있는데, 데이터 분석을 할때 내가 원하는 데이터 타입을 가진 컬럼만을 추출하고 싶을 때 사용을 할 수가 있다.
- 다음 데이터에서 데이터 타입 'object' 를 가진 컬럼만을 추출하고 싶다면
df.select_dtype(include='object')라는 코드를 사용을 하게되면 데이터 타입이 object인 컬럼들만 찾아서 추출하게 된다. 여기서 중요한 것이 include라고 적혀있는 부분이다. 해당 부분의 값이 include가 아니라 exclude라고 작성이 되어있을 경우에는, 내가 찾고자 하는 데이터 타입을 제외한 다른 타입들을 찾아서 추출을 하게 된다. 다음 예시가 아래 사진에 명시되어 있다.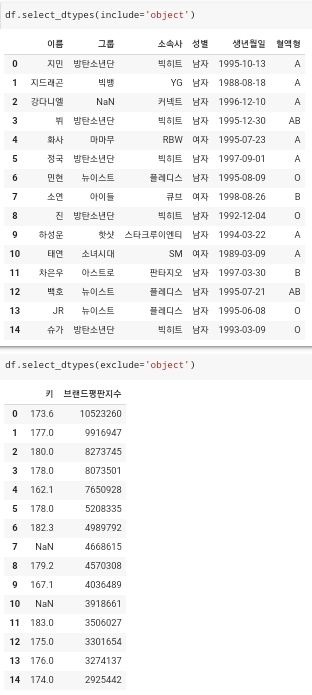
- 위에 include라고 작성된 부분의 결과값들은 모두 데이터 타입이 object로 명시된 값들인 것이고, 아래에 exclude라고 작성된 부분은 데이터 타입이 'float64', 'int64' 로 object와는 다른 데이터 타입들만이 추출된 것을 확인할 수가 있다.
- select_dtype을 사용하여 연산을 진행을 할 때도 위에 데이터프레임 산술연산도 동일하게 적용이 된다. object로 작성된 데이터 값을 산술 연산하게 될 경우에는 오류가 발생하게 되지만, float64, int64로 작성된 데이터에 대해서는 정상적으로 산술 연산이 진행된다는 것을 확인할 수 있다.
- 그리고 특정 변수값에 select_dtype으로 추출한 컬럼값들만 모아서 저장을 한 다음에 저장된 값으로 데이터를 찾을 수도 있다.
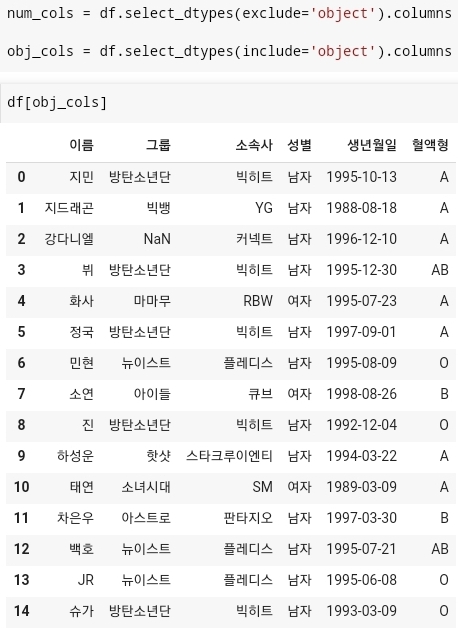
- num_cols에는 정수와 실수형만을 추출한 컬럼명값이 저장이 되어있고, obj_cols에는 object 타입으로 작성된 컬럼명값들이 저장된 것을 확인할 수 있다.
- 다음은 Pandas에서 select_dtypes이라는 함수가 존재하게 된다. select_dtypes은 데이터에서 내가 찾고자하는 데이터 타입의 컬럼값들만 찾아서 결과값을 출력하는 함수이다.
- Ch02.Pandas-전처리-12.원핫인코딩의 개념과 get_dummies
- 원핫인코딩은 한개의 요소는 True 그리고 나머지 요손느 False로 만들어 주는 기법이다.
- 원핫인코딩이 필요한 이유는
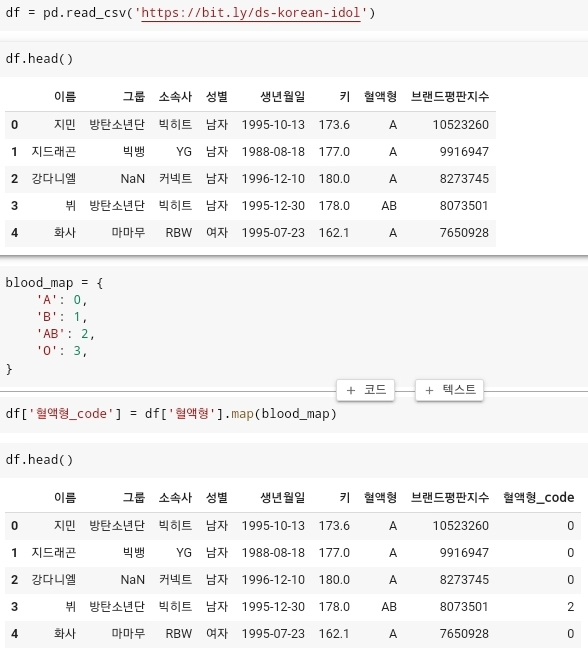
- 다음과 같이 혈액형에 존재하는 모든 값들을 object값이 아닌 int형으로 변환하여 표현을 하는 경우가 있다. 이렇게 변환된 df['혈액형_code'] 를 머신러닝 알고리즘에 그대로 넣어 데이터를 예측하라고 지시한다면, 컴퓨터는 '혈액형_code'안에서 값들간의 관계를 스스로 형성 하게 된다. 이 상황에서 만약 B형인 1, AB형인 2라는 값을 가지고 있는데, 컴퓨터는 B형 + AB형 = O형이라는 잘못된 관계를 맺을 수 있게 된다. 따라서 우리는 4개의 별도의 column을 형성해주고 1개의 column에는 True 나머지는 모두 False를 넣어 줌으로써, A, B, AB, O형의 관계는 독립적이다를 표현해준다. 이것이 원핫인코딩이라고 한다.
- 원핫인코디을 사용하는 방법은
pd.get_dummies()에서 get_dummies()함수 안에 내가 사용하고자 하는 컬럼명을 추가하여 작성을 해주면 된다. 그러면 다음과 같이 나오게 된다.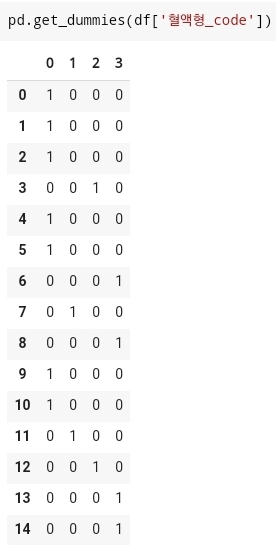
- get_dummies()함수를 활용하는 과정에서 prefix라는 옵션을 사용하게 되면 컬럼명앞에 옵션에 설정한 값이 맨앞에 추가된 값으로 컬럼명이 설정되게 된다.
- 원핫인코딩은 나중에 머신러닝 알고리즘으로 발전하기 위해서는 꼭 알아야하는 개념이다.
- Ch02.Pandas-전처리-13.부동산 데이터로 데이터 분석 실습-문제 설명 / Ch02.Pandas-전처리-14.부동산 데이터로터데이터 분석 실습-해설
- 다음 부분은 실습부분과 해설과정의 내용이 같으므로 같이 작성하도록 하겠습니다.
- 우선 공공데이터 사이트에서 민간 아파트 가격동향이라는 데이터 가져와서 로드시킨다. 로드시킨 데이터에서 컬럼값을 사용하기 편하게 일부분 수정을 해준다.
-
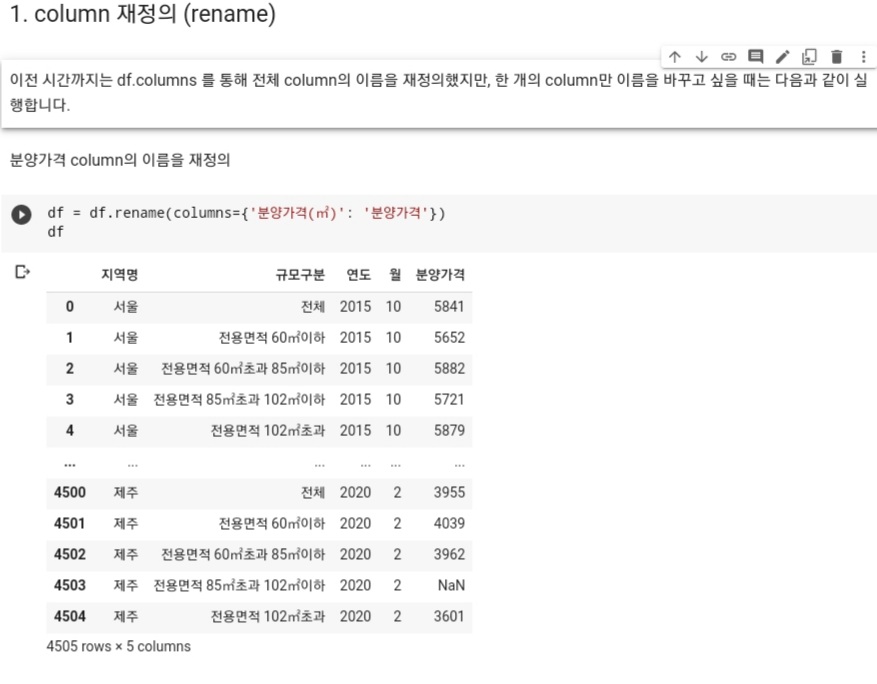
- 그런 다음에 다음 데이터의 타입과 통계 자료를 출력해본다.
-
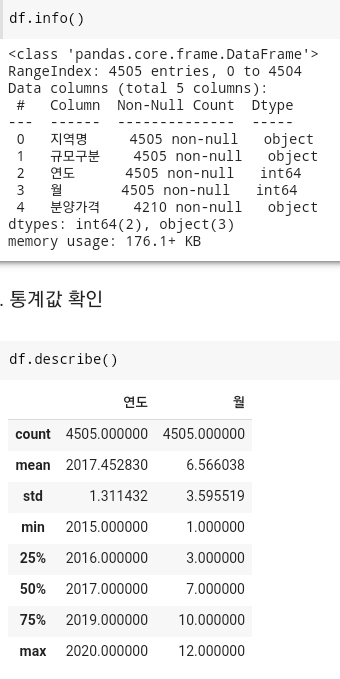
- 여기서 확인한 데이터 값을 보면 특정 컬럼에 결측값이 존재한다는 것을 확인할 수가 있게 된다.
- 데이터 처리를 쉽게하기 위해서 분양가격에 대한 값들을 object -> int 값으로 타입을 변환하겠습니다.
- 하지만 타입 변환을 하는 과정에서 오류가 발생하게 된다. 데이터 내부에는 우리가 변환하기 쉽게 작성된 값들만 있는 것이 아니라 여러가지 데이터 값들이 존재하기 때문에 각 데이터마다 발생하게 되는 오류들을 다 수정을 해주면서 분석을 진행해야 된다.
-
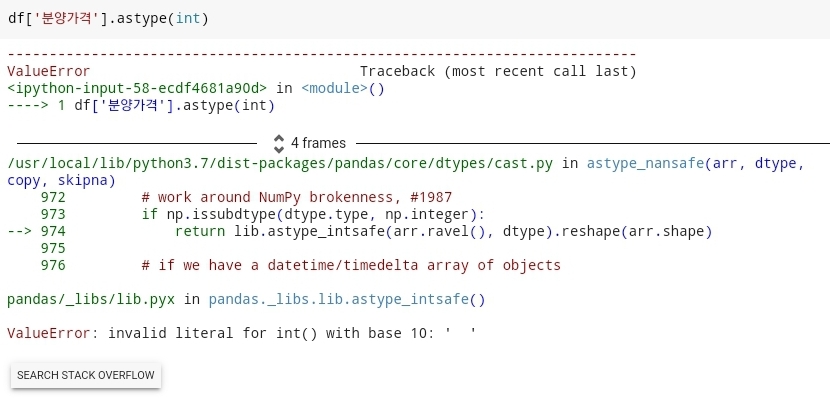
- 맨처음 나타나게 되는 오류사항이다. 다음과 같은 오류는 데이터값에서 공백이 존재하는 값이 존재하기 때문에 발생하게 되는 오류이다. 공백 오류를 없애기 위해서는
strip()함수를 사용하면 해당하는 값에 대한 공백들이 사라지게 된다. 우선 공백이 존재하는 데이터 값들을 찾게 되면 -
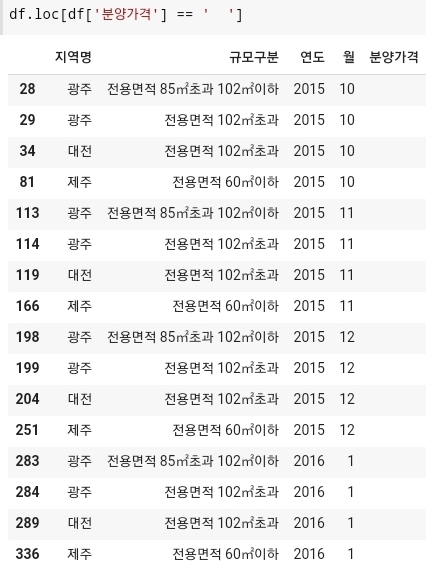
- 다음과 같이 공백이 존재하는 데이터들만 추출되게된 것을 확인할 수 있다. 다음 공백을 없애기 위해서는
df['분양가격'].str.strip()을 사용하게 되면 공백값을 제거할 수 있다. 하지만 이 데이터를 유지하기 위해서는df['분양가격']의 값으로 새로 변경해주면 된다. - 그 다음에 빈 공백이 있는 데이터는
df.loc[df['분양가격'] == '', '분양가격'] = 0으로 '분양가격' 컬럼에서 ''인 값을 찾은 다음에 '분양가격' 컬럼의 데이터만 0값으로 채운다는 코드를 입력해준다. 그리고 다시 한번 타입 변환을 해준다. 하지만 요번에는 NaN값 때문에 오류가 발생하게 된다. 따라서fillna(0)으로 0으로 결측값을 채운다. 그러고 다시한번 타입 변환을 해준다. - 요번에는 데이터 중 '6,657'이라는 콤마(,)가 들어간 데이터가 존재하기 때문에 오류가 발생하게 된다. 해당 값이 존재하는 데이터를 찾아보면
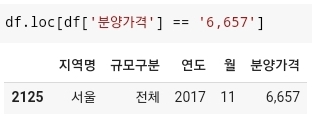
- 다음과 같이 2125행에 콤마(,)가 들어간 것을 확인할 수 있다.
- 콤마는
df['분양가격'] = df['분양가격'].str.replace(',','')코드를 사용하게 되면 6,657 -> 6657로 변경된 것을 확인할 수 있고 해당 값은 다시 '분양가격' 컬럼값으로 적용이 된다. - 그럼 이제 콤마까지 제거를 하였기 때문에 다시 타입 변환을 실행한다. 이번에도 또 NaN값이 존재한다고 하면서 오류가 발생한다. 다음 오류는
.fillna(0)으로 해결하고 타입 변환을 실행한다. - 다음 오류는 데이터중 '-' 값이 존재해서 오류가 발생하게 된다. 다음 오류는 위에서 작성한
replace('-', '')코드를 사용해서 '-'값을 제거하고 다시 한 번더 타입 변환을 실행한다. NaN값으로 인한 오류가 또 발생하게 되는데 이거는 또.fillna(0)코드로 해결한다. 해결이 되면 타입 변환을 다시 실행해준다. 하지만 '' 공백과 관련된 오류가 다시 한번 발생된다. 이것은 위에서 했던df.loc[df['분양가격'] == '', '분양가격'] = 0을 다시한번 실행시켜서 해결을 한다. - 데이터 중 규모구분이라는 column에 불필요한 '전용면적'이라는 단어를 제거한다.
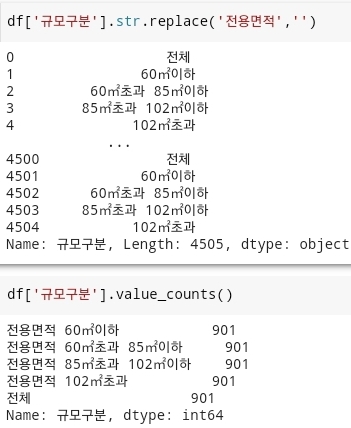
- 그러고 '규모구분'컬럼에서 각 항목별로 갯수가 어떻게 되는지
.value_counts()함수를 사용해서 확인을 해본다. 그러면 각 전용 면적 당 가지고 있는 데이터의 수는 901이라는 값이 나오는 것을 확인할 수 있다. - 이러고 분양가격이 100 보다 적은 값들은 모두 제거한다.
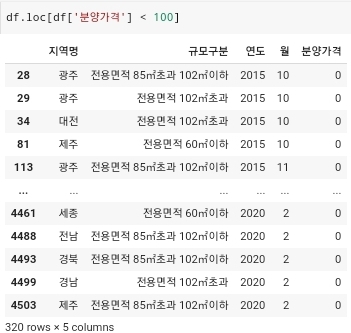
- 분양가격이 100보다 적은 모든 데이터의 index값을 idx라는 변수에 대입한 다음에
.drop(idx, axis=0)함수를 활용하여 idx에 저장된 모든 index 값들을 df데이터에서 제거한다. 이렇게 불필요한 데이터를 모두 제거하고 나면 구하고 싶은 데이터를 구해보면 된다.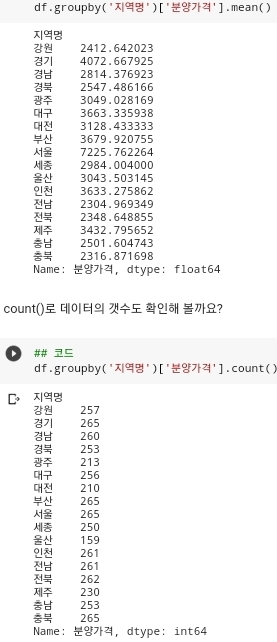
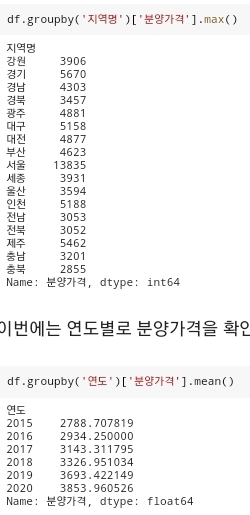
- 지역별 분양가격의 평균, 지역별 분양가격의 수, 지역별 분양가격의 최대값, 연도별 분양가격의 평균 등을 코드로 분석할 수 있다.
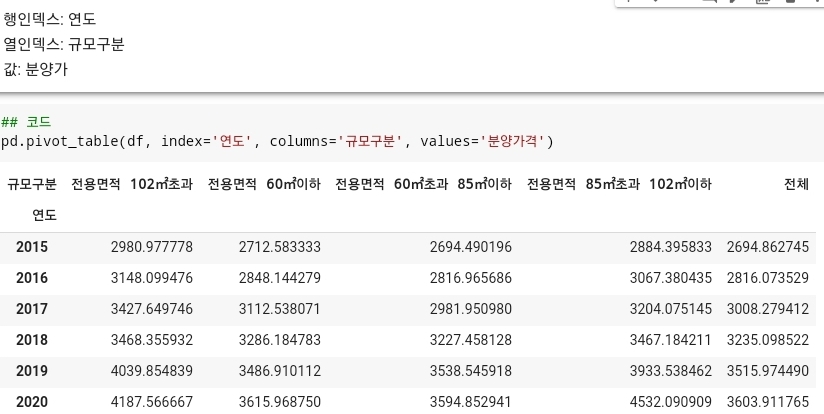
- 피벗테이블을 활용하여 연도와 전용 면적별 분양가격을 확인할 수 있다.
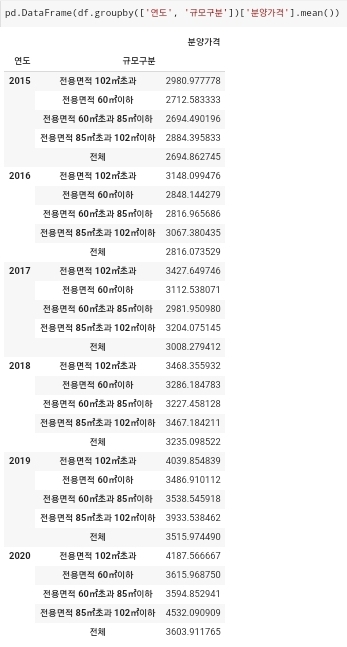
- 마지막으로 데이터프레임 함수를 활용하여 연도, 규모구분 별 분양가격의 평균값을 보기 좋게 출력한다.
- Ch03.pandas-시각화-01.데이터 시각화에 대하여
- 데이터 시각화 : 데이터를 시각적인 관점으로 표현하는 것
- 시각화는 수 많은 숫자 + 문자형으로 된 데이터로부터 사람이 이해하기 쉽도록 그리고 인사이트를 얻을 수 있는 가장 직관적인 시각적 정보를 얻기 위함이다.
- EDA(Exploratory Data Analysis) 탐색적 데이터 분석 : 수집한 데이터가 들어왔을 때, 이를 다양한 각도에서 관찰하고 이해하는 과정.
- 분석 전 EDA 과정은 항상 거치게 되는 과정에 해당한다.
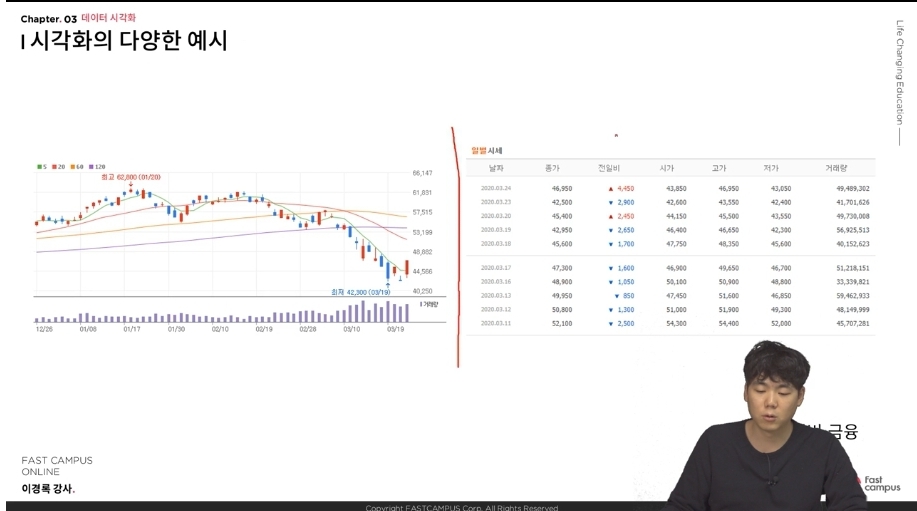
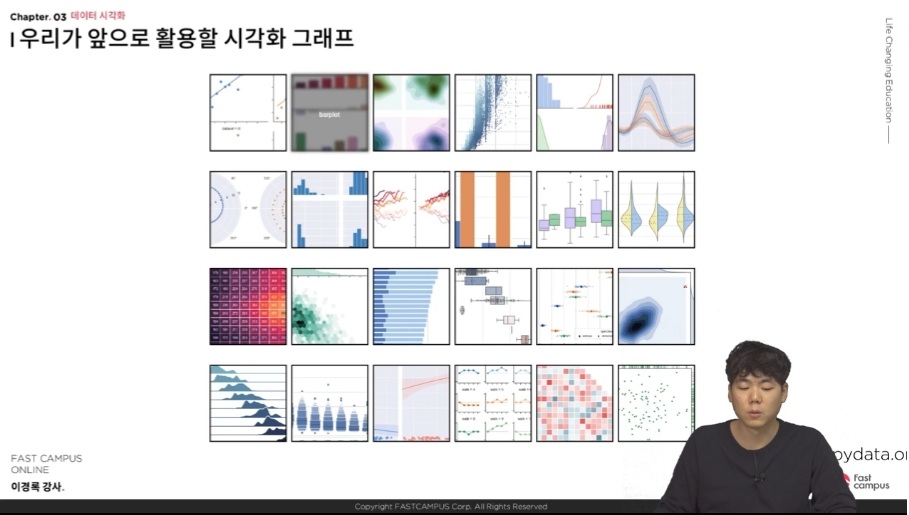
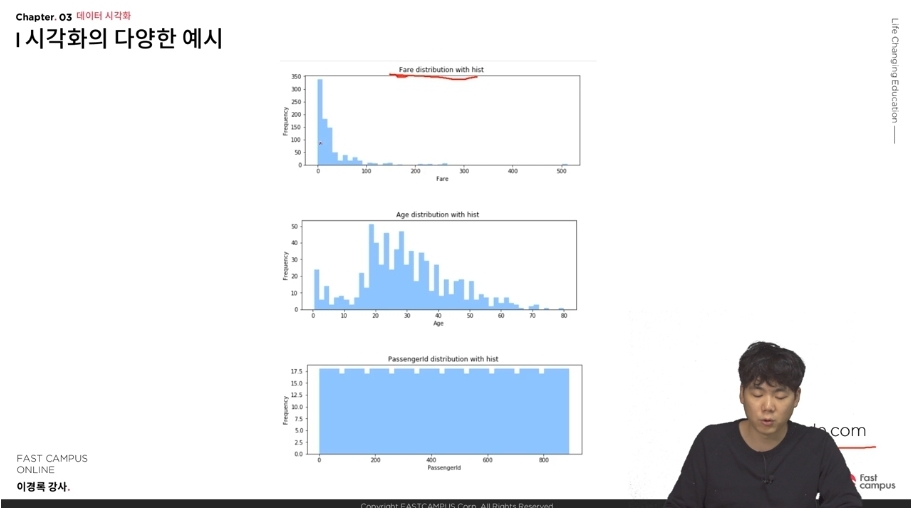
- 다음 사진들은 앞으로 강의를 들으면서 아니면 실질적으로 데이터 분석을 하게 되면 다루게 되는 데이터 시각화를 통한 그래프들이다.
- 데이터의 시각화 (Data Visualization) : 숫자, 문자로 된 데이터를 시각적으로 변환. 가장 직관적인 수단이다.
- Ch03.Pandas-시각화-02. colab 한글폰트 깨짐현상 해결 (시각화)
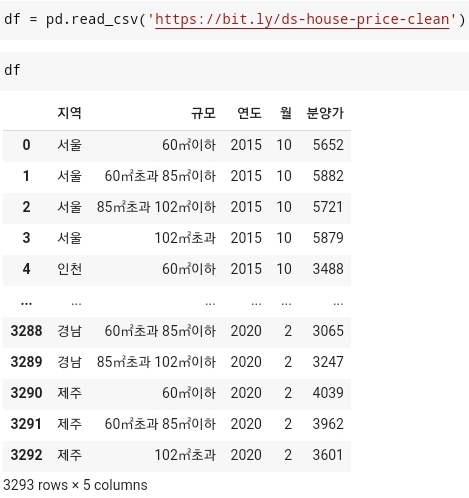
- colab을 사용하여 데이터 시각화를 실행하면서 한글을 사용하는 경우가 있게 되는데, 한글을 사용하게 되면 한글이 깨져서 한글이 제대로 출력되지 않는 경우가 가끔씩 나타나게 된다. 우선 예제로 앞에서 다룬 부동산 데이터를 활용한 시각화를 실행해본다.
- 코드는
df.plot()이다.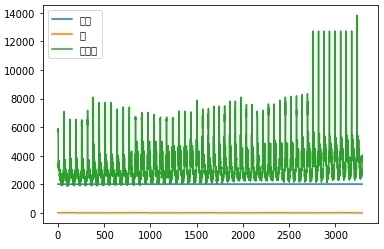
- 두번째 사진을 보게되면 그래프가 생성된 것을 확인할 수 있다. 하지만 왼쪽 상단을 보게되면 네모난 모양으로 된 값들이 존재하는 것을 확인할 수 있다. 해당 부분이 한글이 깨져서 발생하는 문제이다. 다음 문제를 해결하기 위해서는 다음과 같은 코드를 실행시키면 된다.

- 다음 코드를 한번 실행시키고 상단 메뉴에서 런타임을 클릭하고 런타임 다시 시작을 클릭한 다음에 위 사진의 코드를 다시 한번더 실행한다. 그러고 데이터를 다시 로드시킨 다음에
df.plot()을 활용하여 그래프를 다시 생성하면 왼쪽 상단에 깨졌던 한글이 잘 실행되는 것을 확인할 수 있다.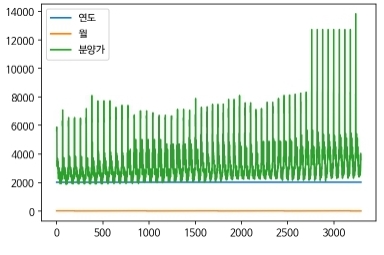
- 그래프의 크기가 좀 작아보인다. 그래프를 크게 하는 방법은 다음 코드를 활용하면 된다.
plt.rcParams["figure.figsize"] = (12, 9) # (넓이, 높이) - ()안에 12는 그래프의 가로 길이에 해당하는 값이 되고, 9는 그래프의 세로 길이에 해당하는 값이 된다. 그래서 내가 원하는 적당한 크기를 괄호안에 입력해서 그래프의 크기를 조절할 수 있다.
이렇게 Pandas 전처리 방법중에서 데이터프레임의 산술연산, Select_dtype, 원핫인코딩의 개념과 get_dimmies, 실제 부동산 데이터로 데이터 분석을 하는 실습, 데이터 시각화에 대한 설명, colab을 활용하여 시각화를 할때 한글폰트 깨짐현상을 해결하는 방법에 관하여 작성해았습니다.
- 데이터 분석
- 홈페이지에서 강의 찾는 방법
패스트 캠퍼스 -> 온라인 -> 올인원 패키지 -> [데이터 분석 강의 보러 가기] -> 직장인을 위한 파이썬 데이터 분석 올인원 패키지 Online. 패스트 캠퍼스 - [데이터 사이언스] 직장인을 위한 파이썬 데이터 분석
https://bit.ly/2MJqrMs
'데이터 분석' 카테고리의 다른 글
| [패스트 캠퍼스 수강 후기] 직장인을 위한 파이썬 데이터 분석 올인원 패키지 Online 14일차 (0) | 2021.03.29 |
|---|---|
| [패스트 캠퍼스 수강 후기] 직장인을 위한 파이썬 데이터 분석 올인원 패키지 Online 13일차 (0) | 2021.03.23 |
| [패스트 캠퍼스 수강 후기] 직장인을 위한 파이썬 데이터 분석 올인원 패키지 Online 11일차 (0) | 2021.03.16 |
| [패스트 캠퍼스 수강 후기] 직장인을 위한 파이썬 데이터 분석 올인원 패키지 Online 10일차 (0) | 2021.03.15 |
| [패스트 캠퍼스 수강 후기] 직장인을 위한 파이썬 데이터 분석 올인원 패키지 Online 9일차 (0) | 2021.03.10 |




댓글